Learn why leading HR professionals trust ekincare! Explore Now

We live in a world overflowing with data, it is like the water of the digital age. At ekincare, our vision is to empower corporates /insurance companies with measurable/ROI-driven wellness programs. So naturally, health data is very important to us and one of the largest untapped sources of health data of an individual is lab reports(in form of PDFs, images).
The trouble with lab reports is that they are unstructured. Structured data can be used for analytics while unstructured data cannot be. Converting lab reports to structured data is essential to generate health analytics for individual/population analytics for an organization.
In India, the diagnostic center industry is very fragmented unlike in the US, where there are no government standards for healthcare data. In the USA, the LOIN-Code uniquely identifies the test components. So no matter, where the individual goes, health data can be collected /interpreted.
The problem in India is that every diagnostic center /hospital has different nomenclature for any test being done. Many diagnostic centers do not have PHR/EHR systems and simply type the lab report into a document and print it. For example, the test component : Fasting Blood Glucose could have any of the following names, depending on the diagnostic center.
Add to this the mistakes that even the state-of-the-art OCR makes while reading text from a scanned image, and we have seemingly endless possibilities of representing the same test.
In addition, different labs have different units to measure the results, which makes reconciling and interpreting lab results from different diagnostic centers a lot more difficult.
A naïve approach would be to use manpower to digitize and structure the lab reports. The problem with this approach is that it is not scalable. It becomes tedious to manually extract every information and its interpretation from the test report.
Deep learning has shown a lot of promise in solving formerly intractable problems (i.e., image recognition, entity detection, etc.). Deep learning uses neural networks that mimic the brain to learn and improve the experience. ekincare Deep Learning models are trained with over 2 lakh lab reports.
Whenever a test report is generated and shared with us in the PDF format (figure 1), it is put through OCR (Optical character Recognition) which converts the PDF into text. From this text, we extract all relevant entities such as test component names, results and ranges using our proprietary model. This model is built from a combination of state-of-the-art Deep Neural architectures consisting of Convolutional Neural Networks and Long Short-term Memory layers.
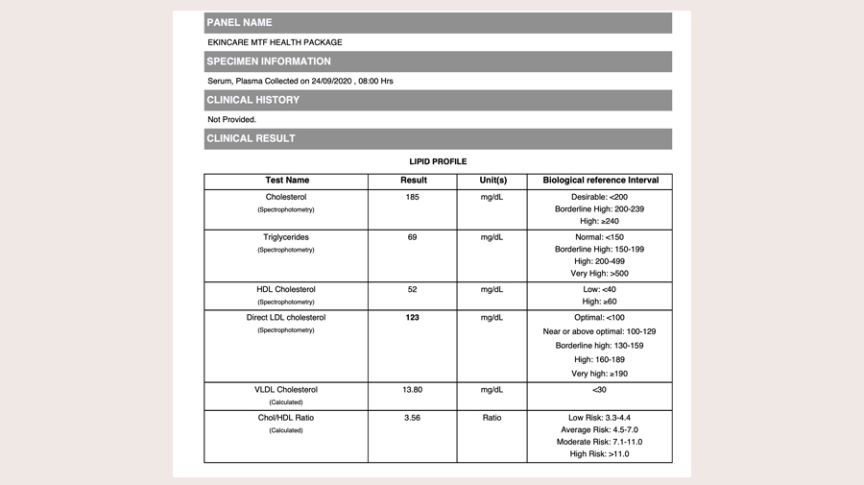 Fig. 1: A Typical Medical Report
Fig. 1: A Typical Medical Report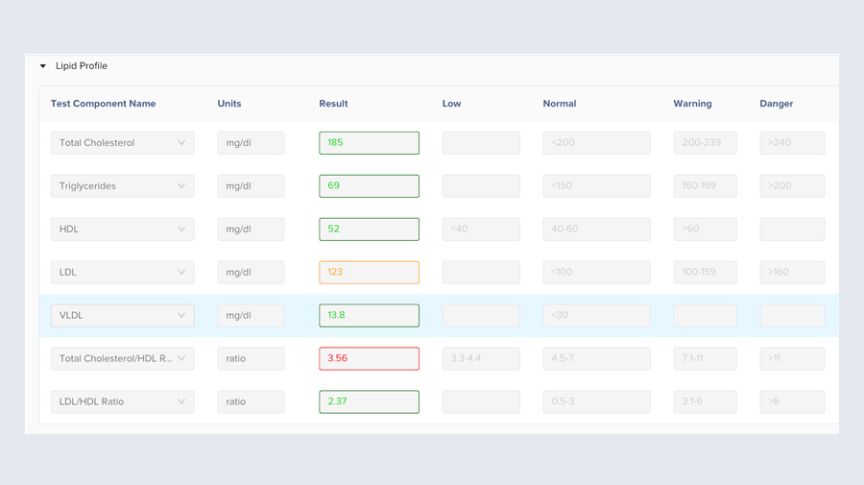 Fig. 2.1: Digitized report
Fig. 2.1: Digitized report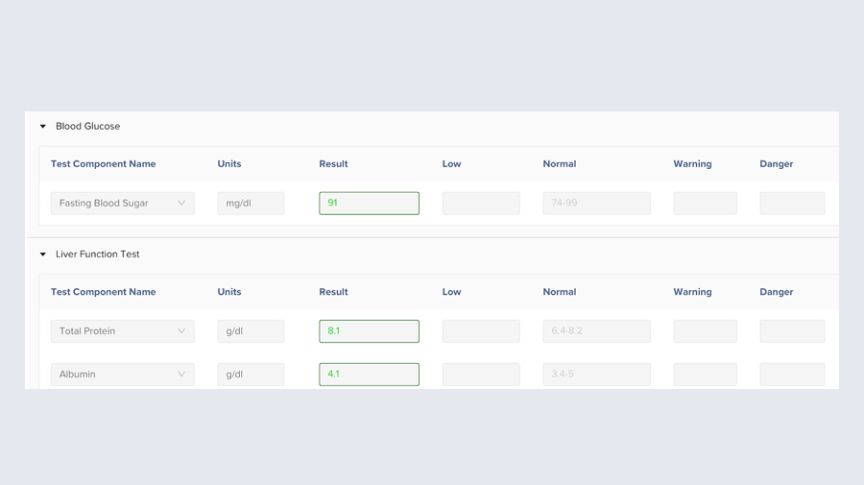 Fig. 2.2: Digitized report
Fig. 2.2: Digitized reportThe model assigns unique identification code (LOINC) for test components so that they can be identified correctly irrespective of the name used by any specific diagnostic center. Further, the model extracts notes (such as for X-ray and ECG reports) written by doctors and displays them in a separate section.
Results are color coded (into green, amber and red) automatically from the provided ranges. This makes it easy for customers and their doctors to quickly glance at the report and determine if any results are outside the normal range. Moreover, digitizing the reports this way enables us to provide customers with historical trends for their health. It also enables us to summarize the general health of all employees of a company and suggest measures to increase their health.
Amazon recently announced its Comprehend Medical service which “uses a pre-trained model to examine and analyze a document or set of documents to gather insights about it.”
Naturally, we were curious on how it would stack up against our model in extracting information from Lab reports. So, here is the comparison.
Both models were presented with a small section of a typical lab report (Fig. 3).
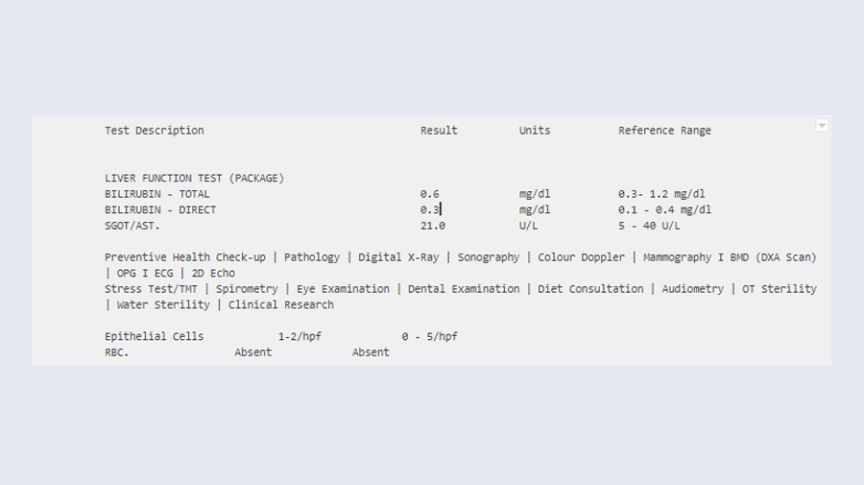 Fig. 3: Sample lab report section
Fig. 3: Sample lab report sectionHere are the outputs given by AWS and ekincare models respectively.
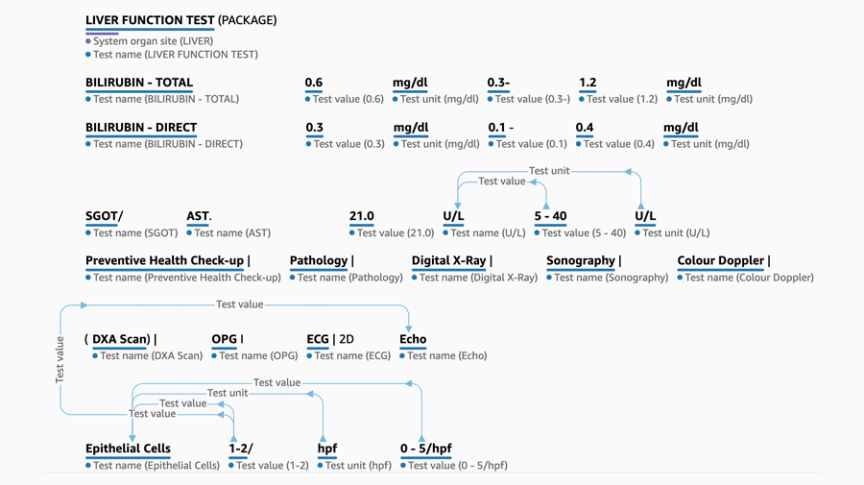 Fig. 4: AWS output to the sample section in Fig. 3
Fig. 4: AWS output to the sample section in Fig. 3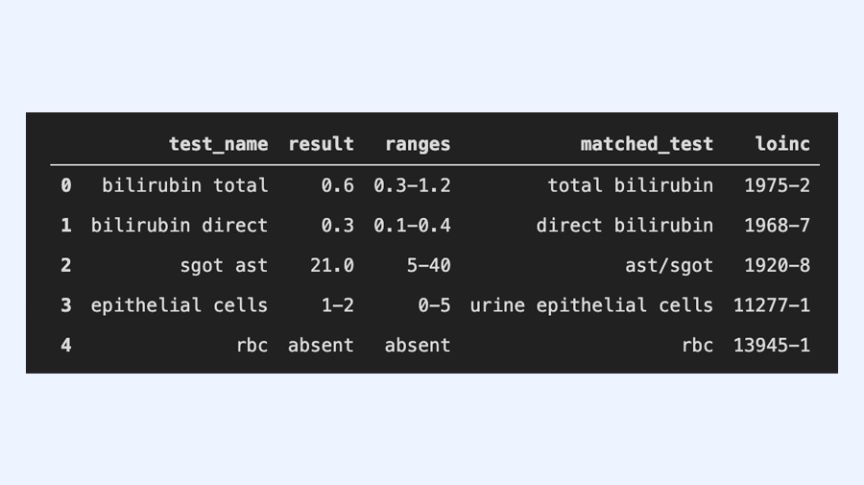 Fig. 5: ekincare output to the sample section in Figure 3
Fig. 5: ekincare output to the sample section in Figure 3While AWS model manages to categorize entities into name, value or unit,
Some tests have categorical results, which could present a certain degree of challenge in identifying them correctly. Our model accurately returns all tests with their corresponding result and ranges- numerical or categorical. Further, it corrects any mistakes that might arise from OCR and provides unique identification code (LOINC) for each test component.
A complication that arises when determining LOINC of a test is that the same test might have different LOIN-Codes depending on which Lab Test they belong to. For example, the test component Red Blood Cells has LOIN-Code 789-8 for Complete Blood Picture, and 13945-1 for Urine Examination. Determining which lab test a given test component belongs to is often difficult and requires contextual awareness. Our model can accurately assign correct LOINC in such scenarios by using predictions from surrounding test components.
Tools like Amazon’s Comprehend Medical are wonderful for making sense of unstructured medical data. They rely heavily on Natural language Processing to accomplish those tasks. While this would really help with analyzing clinical text, lab reports lack the nuances of natural language written by a human, and approaching the problem with the same tools will not yield good results- as clearly witnessed from the above examples. Our model is specifically designed to tackle this particular problem, and outperforms any algorithm available in the market right now.